protobuf 跨语言使用字符串编码问题
好久没更新了..... 这段时间,咳
最近公司项目组有个需求,就是用C++写一个可供 Android 和 WinCE 的跨平台语言底层调用,从下层向上层传递数据。背景是之前项目是在 WinCE 上做的,开发语言是 C#, 现在在开发 Android 的版本,所以想把底层涉密的底层算法用 C++ 重做,同时反馈给之前的 CE 版本。
跨语言调用传递数据主要就是一个协议,因为不管传递什么数据,底层来说都是一丢丢的字节流,这里只要能从字节流中解析出一致的数据就可以。这里准备采用 google 的 protobuf。
官方的 protobuf 默认支持三种语言,C++/Java/Python,支持 C# 的有社区版本,protobuf-csharp-port 。
今天就测试了下从 C++ 传递数据到 C# 中解析的情况,这里暂时没有考虑跨语言直接调用,而是用 C++ 版本 序列化一个文件然后让 C# 版本解析。这之中,如果 .protoc 文件string 定义的字段都是使用 ASCII 编码的话,是没有什么问题的。如果用到中文,这里到 C# 里就会乱码,很常见的编码问题 Orz。主要问题还是 VS 的 C++ 文件编码,因为 VS 默认是 本地编码(中文的就是 GBK),所以里面字符串字面量也是本地编码,如果你把文件编码转换为 UTF-8 无 BOM,会无法编译,如果转换为 UTF-8 带 BOM 格式,VS 编译过程中会把UTF-8带BOM格式文件转换为本地编码.....蛋疼。所以在 C++ 版本里用了一个 GBK 转 UTF-8 的函数,把 GBK 编码的 string 转为 UTF-8 编码的 string,然后序列化。再到 C# 中解析就正常了。如果在 C++版本中不转换而在 C# 中转换编码的话,我找了但是貌似没找到可行的方法。
无力吐槽 VS 的文件编码处理了。统一向 UTF-8 靠拢才是良策。PS: 貌似 C# 默认写入文件编码就是 UTF-8(待确认)。
UTF-8 编码避免了字节序(大小端)问题,适合通信。 UTF-16 就很适合本地使用。
顺便吐槽一下 ParseFromArray 这个 API ,第二个参数必须正好是数组里存放的 message 的 ByteSize 大小,大一点也不行, 所以不能传递数组的大小。原因。所以最好在序列化之前写入 ByteSize 大小用以标识。
pythonchallenge 10: what are you looking at?
python挑战的第10题
http://www.pythonchallenge.com/pc/return/bull.html(需要前面某题的钥匙,登录密码对 huge : file)
问题是 a = [1, 11, 21, 1211, 111221, 求 len(a[30]) = ?
数列的规律在于 后面一个元素是对前一个元素的“读法”,就是数数字,比如 "1211" 里是 1个"1"、1个"2"、2个"1",所以“读法”是"111221",这也就是下一个元素了。
其中一个字符串的“读法”关键是对于连续的同一个数字子序列是合并的读法,如果采用正则来匹配的话,就应该是这样的一个模式
pattern = re.compile(r'(\d)\1*')
(\d)用于匹配一个数字,然后成为一个组,\1就是引用这个组,* 默认是贪婪匹配,这样就可以匹配一个连续相同的数字串了。
用这个模式匹配一个字串后,就可以“读”出来,一个长度加上数字本身
# match 是匹配的 match object
s = match.group(0)
assert s
return "{0:d}{1:s}".format(len(s), s[0])
而对于一个完整的由多个不同数字子串构成的序列元素来说,完整“读法”的计算可以使用正则的 sub 方法
# repl function for regexp.sub
def repl(match):
s = match.group(0)
assert s
return "{0:d}{1:s}".format(len(s), s[0])
# read a digit string, otherwise, the next string
def read_digit_str(str):
# must be a digit string
assert str.isdigit()
return pattern.sub(repl, str)
这里的 sub 替换过程使用的是函数,函数将相同数字构成的串替换为对应的“读法”字符串
然后写一个序列生成器
# generators
def sequence():
s = "1"
while True:
yield s
s = read_digit_str(s)
这样就可以不断的生成序列元素了,如果要计算 a[30] 的长度,可以用内置的 enumerate 函数带索引遍历,完整代码:
# pythonchallenge 10
# http://www.pythonchallenge.com/pc/return/bull.html
#
# sequence: a = [1, 11, 21, 1211, 111221, 312211, 13112221, 1113213211...
#
# puzzle: len(a[30]) = ?
import re
pattern = re.compile(r'(\d)\1*')
# repl function for regexp.sub
def repl(match):
s = match.group(0)
assert s
return "{0:d}{1:s}".format(len(s), s[0])
# read a digit string, otherwise, the next string
def read_digit_str(str):
# must be a digit string
assert str.isdigit()
return pattern.sub(repl, str)
# generators
def sequence():
s = "1"
while True:
yield s
s = read_digit_str(s)
for index, item in enumerate(sequence()):
if index == 30:
print(len(item))
break
len(a[30]) = 5808
未来
Fist Ref: 这一年来
Second Ref: Turing机、人工智能以及我们的世界 ---- Matrix67
Long ago Ref:远比你孤独
这“既定”并非是“宿命感”,我们大脑用来计算的图灵机很难和宇宙这个巨型图灵机对比,不在一个数量级。
“没有”真正的随机数列,因为没有方法去证明它是一个“真正的“随即数列
就像你很难证明自己不是一个“精神病人”
就算是“既定的”,也是无法预测的,只有到了时间才知道结果
至少,这样未来还在自己手中
一个 Python 的 IDE
出差了很久,也就没有更新博客,残念。
/////////////////////////////分割线/////////////////////////////////////
今天看维基百科,看到 了 PyScripter 这么个东东,一个 Python 的 IDE,用 Delphi 写的。
我是个喜欢收藏小工具的淫,尤其是好看的,显然我就被这界面给征服了。。。
功能也比较全,有函数补全提示,语法错误提示等等。有兴趣的赶紧去试一下吧,传送门。
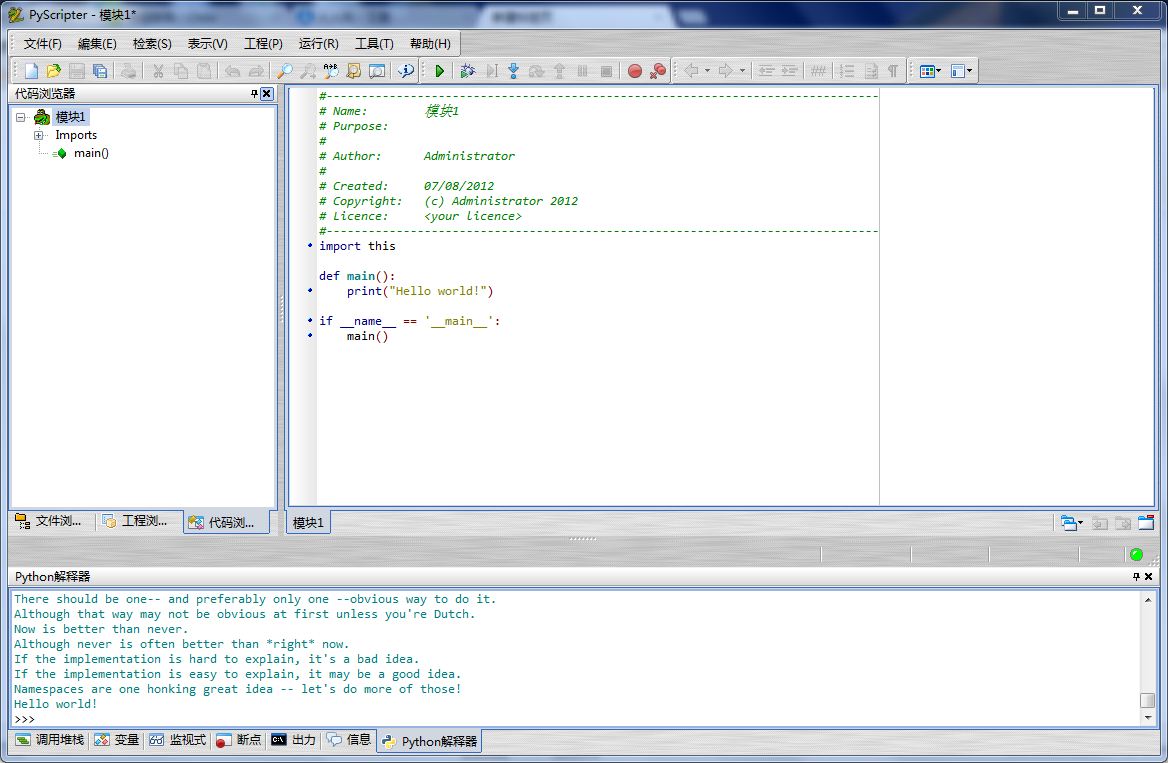
PS: Delphi 果然是做 C/S客户端界面的利器。
使用了互斥量访问全局变量还需要 volatile 吗
今天在看 pthread ,pthread_cond_wait 是个很有趣的函数,至于标题所提出的问题也是困扰我很久的一个“小问题”。
因为“虽然”互斥量能保证多个线程访问全局变量的一致性,但是由于编译器优化和 cache 机制,多个线程对于内存中变量操作也许就没有“真正”反馈到内存里(也许仅仅改变了寄存器中的缓存值),但是这个说法又与互斥量的目的有矛盾(既然都要保证一致性,为什么又“出现”这种内存中“不一致”的状况?)
于是就找资料,终于找到一个很完备的解释:多处理器环境和线程同步的高级话题(白杨) 涉及到 内存屏障 (memory barrier)技术。
至于 pthread_cond_wait 和 pthread_cond_t 的使用,也是有很多需要理解和注意的细节,在这里可以解惑:
http://www.cppblog.com/izualzhy/archive/2011/11/14/160120.html
pthread 的使用教程这里有:http://www.yolinux.com/TUTORIALS/LinuxTutorialPosixThreads.html
不过都是英文,可能在一些细节解释上理解会有难度,不过有搜索引擎还是很容易的,另外也可以参考 《Unix 高级环境编程》也就是所谓的“APUE”。
越来越喜欢 C 的风格和思想了,算是回归吧。
